
こちらの記事は大幅にボリュームアップ(8万文字→30万文字)して書籍化されました!
Link: ドメイン駆動設計入門 ボトムアップでわかる! ドメイン駆動設計の基本
はじめに
この記事は続編です。
前編記事: ボトムアップドメイン駆動設計 https://nrslib.com/bottomup-ddd/
順序立っての説明になっておりますので、前編からご覧になることを強くお勧めします。
ファクトリ
独自の採番システム
ところで UserId は Guid (Globally Unique Identifier)です。
Guid は事実上どこでどのタイミングで生成したとしてもユニークになります。
その性質を利用して User は一意な id をコンストラクタで生成していました。
しかしプロダクトによっては Guid ではなく独自の採番機能を採用したいという事例は往々にしてあります。
そこでデータベースの採番テーブルを利用した独自の採番システムを利用して User オブジェクトをインスタンス化してみましょう。
コンストラクタで SQL を実行して採番しています。このコードは良いものであるとは思えません。
折角リポジトリを利用して、データベースに依存しないロジックが作ることが出来ていたのに、ドメインモデルがデータベースに依存してしまっています。
もし User オブジェクトをテストしたい場合はテスト用のデータベースを用意し、採番テーブルを準備する必要があります。それはため息が出てしまいそうな作業です。
こういった問題を解決しつつ独自の採番の仕組みを取り入れる際にはファクトリが役立ちます。
ファクトリを利用した採番
まずはファクトリの interface を用意します。
このインターフェースを実装しましょう。
CreateUser メソッドの処理内容は採番テーブルを利用して User を生成する処理です。
ファクトリに生成処理が移譲されたことにより UserId を User クラスのコンストラクタで作ることがなくなり、コンストラクタが一つになります。
このファクトリを利用して、アプリケーションサービスに改修を加えてみましょう。
アプリケーションサービスはファクトリのインターフェースを要求しています。
つまりコンストラクタにスタブのファクトリを渡せばテストが行えますし、SQL を用いたファクトリを渡せば採番テーブルを利用することができます。
もし API による採番を行うようになったとしても同様に API を用いた採番を行うファクトリを実装することで対応ができます。
複数システムで共通の ID を利用する必要があるシステム等で活躍するでしょう。
テスト
ファクトリをインターフェースにし、テスタビリティの確保を行いました。
折角ですのでスタブを利用したテストも試してみましょう。
テストの際にはデータベースへのアクセスは行いたくないのでテスト用のファクトリを用意しましょう。
以下はインメモリで稼働する User オブジェクト用ファクトリです。
テスト用スタブなので Id は static で共有して払い出しされる毎にインクリメントしていくようにしておきます。
またテスト用スタブなので並行実行されることへの対処は考えないものとします。
このスタブを利用したテストを作成します。
このスクリプトはデータベースに接続することはありません。
プログラムを実行する環境さえあれば、心行くまでテストをすることができます。
リポジトリによる採番
前節の通り採番処理を行う場合、データベースの採番テーブルを利用する方法はメジャーな選択肢でしょう。
採番処理はデータを永続化する機構と密接な関係にあることが多いです。
その性質から採番処理はデータの永続化に対する知識であると捉えてリポジトリに採番処理を記述する選択肢もあります。
NextIdentity という採番を行うメソッドがインターフェースに追加されました。
このメソッドの実装例は以下のようになります。
採番機能を備えた UserRepository を利用した場合のユーザ作成処理は次のようになるでしょう。
このコードは殆ど問題を引き起こしません。
UserRepository はデータベースについて操作をしているので、同じデータベースに対しての操作である採番処理が UserRepository クラス内に収まっている方が処理がまとまっているように見えます。
むしろファクトリを用意することで同じデータベースに対する操作が分散していることが問題のようにも思えるでしょう。
しかしリポジトリに採番処理を記述することで逆にまとまりがないように思えるパターンもあります。
既にお気づきかと思われますが、前節で記述した API などを利用して採番を行うパターンです。
コードに落とし込んでみましょう。以下が API による採番処理をリポジトリに記述した場合のコードです。
今度はデータベースの処理の中に API を利用する処理がまぎれることになります。
ファクトリに記述するよりもリポジトリに ID 生成の処理を記述した方がよいと感じていた方は尚のこと違和感を感じるのではないでしょうか。
これは私見ですが、リポジトリのインターフェースに採番処理用メソッドを用意するということは、採番処理がデータの永続化装置と密接な関係にあることを示唆しているようにみえます。
Auto Increment
データベースの Auto Increment の機能を利用して ID を振るというパターンも存在します。
Auto Increment による採番処理を採用した場合 ID 生成に関わる煩わしい処理から解放されます。
その代わり識別子のないエンティティという存在を許すことになります。
とはいえ一貫してそのようにシステムを形作り、チームで合意を取れていれば問題となるのは稀なケースでしょう。
トランザクション
これまで作ってきたユーザ登録アプリケーションには実は致命的な不具合があります。
それは同時に実行した際に同じユーザ名のユーザが登録できてしまうことです。
こういった整合性を維持するための一般的な対策はトランザクションです。
DDD におけるトランザクション処理をこの章にて解説します。
不具合の証明
現在のユーザ登録処理はトランザクション処理がありません。
全てのユーザがお行儀よくリクエストを行ってくれるのであれば破綻しませんが、もし二人のユーザが同時に同じユーザ名でリクエストを行うと、重複して登録できてしまいます。
実際にこの致命的な不具合が発生するかどうかをテストを用いて確認してみましょう。
仮説に沿った状況を再現するにはユーザを保存する際にわずかの待機時間を設けて、並列実行すれば再現できそうです。
折角テスト用のスタブがあるので InMemoryUserRepository のユーザ保存処理に遅延をかけてみましょう。
保存を実行する際に1秒の待機時間を追加しています。
一秒も猶予があればその間に、他のリクエストで重複チェックを通してしまうことは可能でしょう。
このスタブを利用して仮説を証明するコードを記述します。
このテストコードは同一ユーザ名で登録を並列実行しています。
実行してみると仮説通りにこのテストは失敗します。
現在のコードは正しく動作しないということが証明できました。
この問題に立ち向かう術を考えていきましょう。
ユニークキー制約による防衛
重複しないようにする仕組みとしてデータベースのユニークキー制約というものがあります。
ユニークキー制約は指定したカラムが重複するような操作が発行された際にその処理を失敗させる機能です。
このユニークキー制約を利用すればユーザ登録アプリケーションは正しく動作するようになるでしょうか。
もちろん正しく動作します。
UserRepository では username というカラムにユーザ名を保存しています。
username カラムにユニークキー制約を付ければユーザ名が重複する場合、自動的にその SQL が失敗してくれるのです。
ユニークキー制約さえつければ重複することはあり得ない(例外が発生する)のでユーザの重複を確認する必要もなくなります。
重複チェックを行うドメインサービスも無くなり、行数も減りいいことづくめですね。
いいえ、ちょっと待ってください。
果たして本当にこれでよいでしょうか。
このソースコードを見て、「ユーザは重複チェックされる」ということを読み取ることができるでしょうか。
「ユーザは重複チェックされる、そして重複は起こってはいけない」というコードは「ユーザ登録」において重要なファクターでないのでしょうか。
特定のインフラストラクチャの機能に頼るのが本当に正しい道でしょうか。
ドメインの知識が SQL に流出するこの方法は良いプラクティスとは言えないでしょう。
ユニークキー制約を準備することはとても良いセーフティネットですが、ソースコードにロジックを語らせるためにはもうひとひねりが必要そうです。
こういったときに利用されるのがトランザクションです。
トランザクションによる防衛
データベースにおけるトランザクションを利用する場合はデータベースのコネクションが必要です。
コネクションをコンストラクタで受け取りトランザクションを利用するようなコードに書き換えてみましょう。
トランザクションの分離レベル (Isolation Level) はファントムリードを防ぐため Serializable(一番厳密)です。
トランザクションを行う場合はそのトランザクションに対する操作は、トランザクションを開始したデータベースコネクションを利用する必要があります。
このためリポジトリも共通のデータベースコネクションを利用するように変更する必要があります。
これらのモジュールを利用したテストは次のようになります。
このテストは重複せず1レコードのみを登録します(データがデータベースに存在している場合削除する必要があります)。
正しく機能するコードですが問題があります。
それはもちろんアプリケーションサービスが特定のインフラストラクチャに依存してしまっているということです。
これまでリポジトリを使ってインフラストラクチャ層を切り離すように努力していたのが水の泡ですね。
システムの整合性を取るためには致し方ない犠牲と諦めたくありません。
これを解決する一つの方法としてトランザクションスコープがあります。
トランザクションスコープによる防衛
そもそもトランザクションとは何なのでしょうか。
整合性が必要なひとまとまりの処理がトランザクションです。
つまりトランザクションはデータベースに限ったことではありません。
ビジネスロジックの観点から捉えると、その処理を行う間整合性が保たれていればよく、トランザクションの実現方法には興味はありません。
トランザクションの実現方法がデータベースの機能であるという情報はドメインにとっては些末な事柄です。
トランザクションスコープはトランザクションの範囲を明示的にする機能です。
このトランザクションスコープを利用するとトランザクションを実現するための詳細なコード(con.BeginTransaction()といった処理)については表に出さないようにすることができます。
トランザクションスコープを利用した場合のコードは以下の通りです。
RegisterUser メソッドの処理はトランザクションで括られており、ユーザを保存できて初めてそのトランザクションが完了するということが読み取れます。
この変更の結果、アプリケーションサービス上に MySqlConnection が現れなくなり、特定のインフラストラクチャに左右されずに整合性を必要としていることを主張できています。
※トランザクションスコープはトランザクションスコープ内で発生したデータベースコネクションのオープンなどに呼応してトランザクションを開始しています。
他のプログラム言語でのスコープの表現方法
アスペクト志向(AOP)を実践できる言語であればトランザクションであることを明示的にすることができます。
Java のアノテーションや Python のデコレータ等の機能です。
以下は同じアプリケーションサービスですが Spring フレームワークを利用した場合の Java のコードです。
Transactional アノテーションにより、このメソッドは実行前に自動的にトランザクション開始処理が実施され、またメソッド終了時にコミット処理が発生します。
C# の TransactionScope と異なり、メソッドの宣言文を見るだけでトランザクション処理が起きるということが明示的です。
ユニットオブワーク
Unit of work というパターンがあります。
業務のトランザクションを作業の単位として保持するための仕組みです。
日本語に訳すと Unit (単位) of Work (作業) パターンで、作業の単位そのままですね。
ユニットオブワークとリポジトリを組み合わせる場合は、リポジトリをインスタンスとして保持するパターンが多いようです。
このインターフェースを実装してみましょう。
以下は SQL 版のユニットオブワークです。
UserRepository もコネクションを外部から受け取るように修正する必要があります。
これらのインフラストラクチャを利用してアプリケーションサービスを書き換えてみましょう。
トランザクションスコープがなくなり、ユニットオブワークのコミットやロールバックを利用するようになりました。
try-catch の構文が出てくるようになりましたが、導入のしやすさは前節のトランザクションスコープに比べると容易です。
データベースコネクションをそのまま採用できるので、古いロジックはデータベースコネクションをそのまま利用し、改修を加える部分だけユニットオブワークとリポジトリを使うといった芸当も可能です。
デメリットとしてはリポジトリが増加するたびにユニットオブワークに修正が必要になることでしょうか。
モデルの追加に伴ってユニットオブワークの修正が必要になることを避けるには、リポジトリを抽象化する必要があります。
とはいえリポジトリを抽象化すると IRepository
また、もしも登録されていないモデルのリポジトリを要求した場合、リポジトリが見つからないランタイムエラーとなるでしょう。
C# を利用している方でユニットオブワークに既視感を感じる方がいるかもしれません。
実は C# の EntityFramework の DBContext がまさにユニットオブワークの実装です。
エクササイズ
新しい要素のファクトリとトランザクションを利用してエクササイズをしましょう。
サークルシステム
前回作ったシステムを一部流用しながらサークルシステムを作っていきます。
サークルシステムは SNS でよくあるシステムです。
ゲームのギルドやチームなどと言い換えてもよく、同じ趣味や活動を行う集団を作る機能です。
サークルはユーザが自由に作ることができ、そのサークルにユーザが参加します。
サークルを作ったユーザはそのサークルのオーナーになるということにします。
早速サークルに関係する処理を行うアプリケーションサービスを用意します。
サークルにどんな機能を持たせるにしてもサークルがなくては何も始まりません。
サークルを作るユースケースは必ず必要なものでしょう。このユースケースを達成する処理を作成していきます。
まず Circle オブジェクトを準備します。サークルの機能については何も考慮していないので、サークル名が付けられる程度に留めておきます。
CircleId は Circle の識別子で値オブジェクトです。実装自体は UserId と同じなので省略します。
サークルを作る機能はファクトリで用意します。
サークルはオーナーになるユーザを特定する必要があります。
つまり特定の UserId を引数に必要とするでしょう。
また生成したサークルは永続化する必要があるでしょう。
永続化を担当するサークルのリポジトリです。
ファクトリとリポジトリ、それぞれの具象クラスを実装する前に先にサークルを作る処理を完成させましょう。
さて出来上がったこの処理は的確なものでしょうか。
思い出してください。
サークル機能のストーリーは「サークルはユーザが自由に作ることができ、そのサークルにユーザが参加します。」というものです。
つまりサークルを作るのは「ユーザ」です。
改めてコードを見てみましょう。
この処理は「特定のユーザがサークルを作る」という処理でしょうか。
ユーザを取得してそのユーザの ID を利用してファクトリを利用してサークルを作っているのは CircleApplicationService です。
つまりこの処理は「サークルはユーザが作る」ということを表現できていません。
それでは「サークルはユーザが作る」という考えが間違っていたのでしょうか。
間違っているかどうかは正直なところわかりません。思い描いたストーリーが場合によっては間違っていたというケースもあります。
しかし少なくとも「サークルはユーザが作る」ということは表現することはできます。
「サークルはユーザが作る」ということを表現するようにコードに改修を加えると次のようになります。
たった一行の違いです。
もちろん User オブジェクトにはサークルを作る機能を用意する必要があります。
「特定のユーザがサークルを作る」という処理をコードで表現することができたかと思います。
また同時にオブジェクト指向らしくない getter を利用したコードがアプリケーションサービス上から消えました。
サークルに所属する
サークルは人が集まらなくては意味がありません。
サークルにユーザを所属させる機能を実装しましょう。
ユーザがサークルに所属するという処理はユーザの機能でしょうか。サークルの機能でしょうか。
つまり
- UserApplicationService に実装されるべきか
- CircleApplicationService に実装されるべきか
ということに言い換えてもよいです。
これについてはユーザがサークルに所属したとき変化が起きるのは User か Circle かを考えると CircleApplicationService に機能を実装する方が自然に思えます。
CircleApplicationService に「ユーザを所属させる処理」を記述してみましょう。
サークルにユーザが所属できるように変更
Circle オブジェクトには現在ユーザが所属するためのインターフェースがありません。
ユーザが所属できるように List でユーザを保持するようにしましょう。
この Circle オブジェクトを利用してサークルに所属する処理は以下のようになります。
この処理は間違いなく動くでしょう。
しかしこれは正しくビジネスロジックを表現しているのでしょうか。
この処理を読み解くと「サークルのユーザ一覧を取得してその一覧にユーザを追加する」という意味です。
本来のビジネスロジックは「サークルにユーザを所属させる」というものです。
そういった意味では正しくない処理といえるでしょう。
もしサークルの最大人数に制限を加えた場合はどうなるでしょうか。
このコードは最大人数に制限があることを表現できています。
しかし、最大人数に関係するロジックが他の処理でも必要になった際には同様のコードをコピー&ペーストする必要が出てきそうです。
コピー&ペーストを繰り返した後に「最大人数をやっぱり50人にしよう」という鶴の一声があったら何か所も修正する憂き目に遭いそうです。
アプリケーションサービスはビジネスロジックを含まないものです。
ビジネスロジックはドメインモデルに記述されるべきものです。
このようなコードを許すことはドメインモデル貧血症を助長します。
この処理はどのようにすればビジネスロジックを体現したドメインモデルになれるのでしょうか。
それを説明するために集約という概念の解説を行おうと思います。
集約
集約という言葉を聞いたことがない方も多いと思います。
この集約と呼ばれる概念はドメイン駆動設計の中でもとてもイメージがしづらい概念です。
集約ルート
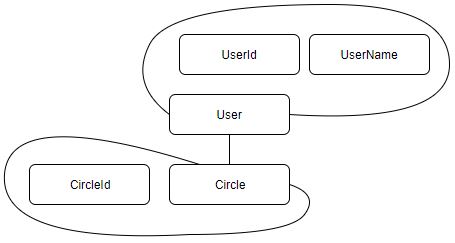
集約は値オブジェクトとエンティティを保持することができます。
User 集約は値オブジェクト UserName 等を保持しています。
Circle 集約は User エンティティを保持しています。
集約にはルートとなるエンティティが存在します。そのエンティティのことを集約ルートと表現します。
User エンティティは User 集約の集約ルート(AggregateRoot)であり、Circle エンティティは Circle 集約の集約ルートです。
集約ルートのみが直接のインターフェース
アプリケーションサービスから操作できるのは集約ルートのみです。
集約内部のエンティティや値オブジェクトを操作できるのは集約ルートのみです。
先ほどのコード
これは集約内部のエンティティ(Users)を操作しています。
集約のルールに違反しています。
これをアプリケーションサービスで実装しないようにするには Circle オブジェクトにメソッドを増やすのがよいでしょう。
Circle オブジェクトは集約ルートですので集約内部のオブジェクトを操作してかまいません。
ユーザを所属させるときは Circle.Join を必ず通ることになるので、最大人数に関係したチェックはこのメソッド内部で行うこともできます。
結果としてユーザの最大数は30人であるという知識がドメインモデルに記述することができています。
整合性の境界としての集約
集約はトランザクションの単位で切り出すとよいとよく言われます。
トランザクションは整合性が必要な処理単位のことを指し、トランザクションで切り出された範囲をトランザクション境界と表したりします。
トランザクションの単位という切り口がわかりづらい場合はデータ変更のための単位という説明の方がわかりやすいでしょうか。
何故そのように言われているかは実際にこれに違反してみると体感することができます。
敢えて違反するようなことをしてみましょう。
例えば Circle 集約は Users を保持しています。
Users は User 集約のコレクションです。
クラスとしては同じスコープに存在していますが、集約という概念上 User 集約は Circle 集約に所属しません。
集約はデータの変更の単位です。
Circle は User をコンポジション(保持)しますが、Circle の情報を変更するときに User の情報を変更してはいけません。
そこで、本来データの変更の単位ではない Circle 集約で User の内容が変更されることを受け入れてみます。
ユースケースとして大分違和感がありますが、一旦受け入れてください。
この処理を通常起こりうるケースとして捉えたとき、リポジトリの実装はどうなるでしょうか。
Circle オブジェクトがコンポジションする User オブジェクトが変更されることがあると想定し CircleRepository の保存処理を実装しました。
Circle オブジェクトに集中すべき CircleRepository の処理内容の大半が User オブジェクトに対する処理で汚染されています。
UserRepository にもほぼ同様のコードが存在しているのでコードの重複も発生しています。
重複することが必ずしも間違いというわけではありませんが、これは不必要な重複にあたるでしょう。
これを防ぐためには Circle オブジェクトでは User オブジェクトの変更は担保しないというルールにしてしまえば問題は解決します。
Circle 集約ではトランザクション境界から外れている User 集約のデータ変更には関与しません。
結果として t_user テーブルに関する処理(知識)を CircleRepository に記述する必要がなくなります。
リポジトリを作る基準として
リポジトリは集約毎に用意します。
整合性の単位が集約ですから、集約に対応するようにリポジトリを定義しておけば変更を過不足なく永続化できるからです。
変更不可能の担保
前節で Circle オブジェクトでは Circle オブジェクトが保持している User のデータ変更は担保しないということにしました。
しかしながら、依然として User の情報を変更することができてしまいます。
変更しないと決めたからにはこの処理は間違いです。
ここでの問題は変更しないと決めたことに「逆らっていること」ではなく、「変更できてしまう仕組み」が問題となります。
変更できてしまう仕組みが問題ならば変更できない仕組みを作ればよいのです。
では、変更できない仕組みを達成するためにはどのようなアプローチがあるでしょうか。
集約を保持しない方針
そもそもトランザクション境界の外側に位置する User オブジェクトを Circle オブジェクトが保持していることが問題と捉えるアプローチがあります。
つまり Circle オブジェクトは所属するユーザ情報を User オブジェクトで保持しないようにするという選択肢です。
User オブジェクトを保持しなければ、User オブジェクトに対する変更処理を実行することができなくなります。
エンティティには識別子があります。User オブジェクトの識別子である UserId を保持するように変更してみたらどうでしょうか。
Users というプロパティは UserId のコレクションになりました。
これにより User の情報を Circle オブジェクトを経由して変更することが不可能になります。
公開しない方針
User オブジェクトのデータを変更できてしまう原因の一つに「オブジェクトの外部に Users を公開してしまっている」というものがあります。
すなわち getter です。
アクセスレベルを private に保持すればクラスの内部でわざわざ情報を変更しない限り User オブジェクトの情報を変更できないことになります。
一旦すべてのデータを隠蔽してみましょう。
このオブジェクトを使ったアプリケーションサービスは次のようになります。
targetCircle.Users.Add(joinUser) とは書けなくなりましたがメッセージ性は損なわれていません。
リポジトリの処理も実装してみましょう。
隠蔽した結果所属しているユーザの UserId まで取ることができなくなってしまいました。
Scala のスコープ限定子などの機能があれば、private なメンバーでも特定のクラスに公開することは可能ですが、多くはそういった機能をサポートしない言語が多いでしょう。
C# 等では internal という同じアセンブリであることを条件に公開するというアクセサもありますが、同一アセンブリに所属させないといけないという制約がネックです。
プロダクト用のモジュールとテスト用のモジュールが同居しなくてはいけなくなってしまいます。
そうなるとやはり getter を公開し、チームで「リポジトリ以下でのみ getter を利用する」という合意を取るというのが現実的な妥協点であると言えるでしょう。
nrs の回答
ここは私個人の回答です。ご注意ください。
こんな方法なら属性を隠蔽することができる、という例です。
カプセル化の観点で public というアクセサは気軽に使うものではありません。
getter を用意することによって、オブジェクトの堅牢さは弱まります。
例えば List を公開している Circle オブジェクトはこんなことができてしまいます。
誰も所属しない Circle という本来ありえないオブジェクトが生まれてしまいました。
これを防ぐために Users を取得するときは List を作り直したりすることもあります。
もしくは読み取り専用のコレクションを使う手もあるでしょう。
このどちらのクラスであっても先ほどの
という処理は記述できてしまいます。
実際はクリアする処理がオブジェクトに影響を与えなかったり、ランタイムエラーでプログラムが異常終了するのですが、コンパイルが通るということが問題と考えます。
これに対する解決策として通知パターンがあります。
Circle オブジェクトに通知パターンを適用する場合 Circle の内情を伝える通知インターフェースを用意します。
そしてこのインターフェースを受け取り private な変数を伝えるメソッドを Circle オブジェクトに作成します。
以上で準備は完了です。
リポジトリで Circle のオブジェクトを保存するために Circle の内情を通知してもらうクラスを実装しましょう。
今回は Builder としてデータのクラスを別に定義しましたが CircleNotification クラスがそのまま getter を公開する形でも構いません。CircleNotification が getter を公開したとしても集約には影響がありません。
これらのオブジェクトを利用して記述したリポジトリの実装は次のようになります。
getter がなくなり Circle オブジェクトのデータは完全に隠蔽することができています。
もちろんこの手段は冗長性を増しています。
この冗長さに対する対抗手段としては、クラスのフィールドを捜査して Notification インターフェースを自動的に実装するツールなどを作成したりするとよいでしょう。
終着地点と出発地点
以上でボトムアップドメイン駆動設計は終わりです。
ドメイン駆動設計の学習を進める上で持っておくとよい予備知識は網羅できたものと思います。
技術書を予備知識なしで読み解くことは困難です。
例えば機械学習の書籍は数学の知識があることを前提とする場合が多いです。
初学者として機械学習の書籍読むとそれらの知識がないことに躓き、「数学を学び直す」か「諦めるか」の選択を常に迫られます。
結果として「数学」という余りにも巨大なコンテンツに打ちのめされ諦める選択をします。
もちろん機械学習を学ぶというだけであれば数学を全て学ぶ必要はありません。
しかし、初学者はどれが機械学習に必要な数学で、どれが機械学習に不要な数学なのか、判断がつかないのです。
ドメイン駆動設計の書籍も同じようなことが起きています。
前提としてある程度のオブジェクト指向の知識や実装知識が求められます。
今あなたはリポジトリを知っています。
しかし初学者はどうでしょう。
リポジトリという言葉を初めて見聞きすると同時に「リポジトリは永続化技術をカプセル化します」と言われてもピンとこないのです。
ここまで読み切ったあなたはドメイン駆動設計に出てくるパターンを大方網羅できています。
ドメイン駆動設計を利用したコードの雰囲気も掴めていると思います。
今のあなたはドメイン駆動設計の本を読んでリポジトリの実装をイメージしながら読むことができるのです。
つまりドメイン駆動設計の概念に集中する準備が整ったのです。
この記事の終着地点にたどり着いたあなたは今、出発地点に立ちました。
もし、ドメイン駆動設計に興味が湧いたのであれば Eric Evans 氏の著書「エリック・エヴァンスのドメイン駆動設計」を手に取ってください。
目次には見知った言葉が並んでいることでしょう。
リポジトリという言葉に恐怖することもないでしょう。
実装が思い浮かぶでしょう。
ボトムアップドメイン駆動設計で実践してきたドメイン駆動設計は形を踏襲しただけの紛い物です。
原典では個々のパターンの繋がりが想像しづらいので、それらの繋がりがわかるように動くものを用意したに過ぎません。
ドメイン駆動設計のマインドは原典を読んで感じ取ってください。
この記事がドメイン駆動設計を学ぶ一助になれば幸いです。
ソースコード
後編用のソースコードは前編とは別のリポジトリにしています。
https://github.com/nrslib/BottomUpDDDTheLaterPart